
Generative AI. Large, creative AI models will transform lives and labour markets
The Economist [2023], "Generative AI. Large, creative AI models will transform lives and labour markets", The Economist, London, 22 de abril, https://www.economist.com/interactive/science-and-technology/2023/04/22/...
Las capacidades de la inteligencia artificial (IA) generativa han provocado gran entusiasmo pero también gran preocupación por su rápido despliegue y desarrollo, no solo en la industria tecnológica sino también en otras esferas de la vida pública.
Hablar de IA generativa remite a todos aquellos modelos que producen contenido audiovisual y escrito de todo tipo, pero la presente entrega de The Economist se focaliza en hablar sobre los grandes modelos de lenguaje (LLM, por su sigla en inglés), una categoría de la IA generativa.
La algazara por esta innovación inició con la aparición pública de ChatGPT, propiedad de OpenAI y su poderoso motor—recientemente actualizado—GPT-4 (dato crucial 1), el cual brinda una poderosa herramienta que redefine la manera de adquirir conocimiento. Con ello, varias empresas tecnológicas han sacado sus propias versiones, a modo de ejemplo Alphabet, Amazon y Nvidia con PaLM, Titan, Megraton, en el orden dado, e incluso modelos independientes como Chinchilla.
El atractivo crece
No obstante, también ha crecido el temor sobre este tipo de modelos de IA considerándolos un riesgo existencial. Las demandas de la opinión especializada han llamado a un cese temporal de los estudios sobre IA puesto que pueden representar (en su opinión) una gran amenaza incluso para la existencia de la humanidad. Mientras tanto, algunos gobiernos como los de Estados Unidos, Europa y China ya están empezando a diseñar reglas para regular esta tecnología.
Para entender los alcances y los riesgos conviene entender el funcionamiento de la IA generativa.
En la década de 2010 se popularizó la técnica de deep learning —en español, aprendizaje profundo— que combina grandes cantidades de datos en poderosas computadoras que ejecutan redes neuronales en unidades de procesamiento gráfico (GPUs, por su sigla en inglés). Esta técnica puede considerarse un antecedente de la IA. El deep learning mejoró la habilidad de las computadoras para reconocer contenido audiovisual y participar en juegos en línea.
Durante el fin de la década de 2010, las computadoras ya eran capaces de realizar muchas tareas humanas y estaban mejor integradas con otros programas tales como los gestores de correo electrónico. Se relata que para los no conocedores o ajenos al tema, la experiencia de interactuar con IA era inefable (dato crucial 2).
En este sentido, los LLM —traducidos de manera práctica como chatbots— han permitido a los usuarios experimentar esta misma sensación de inefabilidad que genera ChatGPT y sus homónimos que los atrapan con su dominio del conocimiento humano. Sin embargo, detrás de todos estos sentimientos apabullantes, los LLM se remiten únicamente a un gran ejercicio de estadística.
Para efectos prácticos se enlista la manera en que opera un LLM:
1) El lenguaje de la consulta (la pregunta que el usuario hace al LLM) se convierte de palabras a un conjunto representativo de números. GPT en sus versiones 3 y 4, realiza esta tarea dividiendo el texto en tokens (trozos de caracteres) como las palabras “amor”, verbos como “son”, prefijos como “des” y signos de puntuación como “¿?”. Cuanto más texto pueda asimilar el modelo más contexto podrá comprender y mejores respuestas dará. No obstante, para respuestas más largas se necesita una mayor capacidad de procesamiento (datos cruciales 3 y 4).
2) El LLM despliega su “red de atención” para establecer conexiones entre las distintas partes de la pregunta. Las asociaciones y nexos entre palabras en los LLM operan de diferente manera que en el cerebro humano; esta debe aprender asociaciones desde cero durante su fase de entrenamiento, así su red de atención codifica lentamente la estructura del lenguaje que “ve” como números (llamados pesos) dentro de su red neuronal. No se trata de un aprendizaje o entendimiento de la gramática sino más bien un conocimiento adquirido en base a las estadísticas. Es más un ábaco que una mente.
3) Auto-regresión: la primera palabra que genera el LLM se basa únicamente en la pregunta para volver a introducir el resultado en si mismo. La segunda palabra se genera incluyendo la primera palabra en la respuesta, la tercera palabra se genera en base a las dos primeras generadas y así sucesivamente hasta que el LLM termina de completar lo que se le ha solicitado.
Todo lo anterior se traduce en solicitarle a ChatGPT (por ejemplo), completa la frase: “La promesa de los grandes modelos de lenguaje es que ellos…” y obtiene el resultado en cuestión de segundos.
Las habilidades de los LLM superan a otras IAs, su éxito reside en los datos de entrenamiento o en las instrucciones que se le dan, no obstante las respuestas no serán del todo predecibles puesto que el tamaño del LLM (la capacidad de procesamiento de datos) está limitado. Por ejemplo, un LLM ni al azar ni por entrenamiento inducido puede generar frases en alemán que incluyan el género, necesita de un modelo más grande. No obstante, a pesar de esta restricción, estos modelos de lenguaje han demostrado grandes habilidades y un potencial enorme; estas características positivas son las causantes de incertidumbre, pues no se sabe a ciencia cierta que es lo que puede venir si la capacidad de los LLM se hace más grande. Algunos estudios puntualizan que en la medida que crece su capacidad es propenso a generar sesgos sociales.
Procesar los datos
Resumiendo, el éxito de los LLM se debe a las grandes cantidades de datos, algoritmos capaces de aprender de ellos y finalmente el poder computacional, añadiendo un extra, el entrenamiento. De lo que se tiene seguridad es que si este tipo de modelos no entrena lo suficiente, los pesos en la red neuronal de GPT-3 serán en su mayoría aleatorios, y como resultado, el texto de salida será confuso y desordenado (datos cruciales 8 y 9).
La ventaja es que un LLM puede entrenar por si mismo puesto que las respuestas que entrega se encuentran en los mismo datos que procesa. De esta manera, primero se cuestiona sobre la solicitud que se le escribe, luego toma una muestra y las cubre con algunas palabras al final, posteriormente trata de adivinar qué podría ir allí. Entonces el LLM descubre la respuesta y la compara con su información anterior.
Así, el objetivo de un LLM es generar la mayor cantidad de conjeturas buenas minimizando la cantidad de errores (algunos mejores que otros), también llamado pérdida. Cuando el LLM genera conjeturas de pérdida, esta se envía de vuelta a la red neuronal y se usa para empujar los pesos en una dirección que produzca mejores resultados.
Pionero en un aturdimiento
Para hacer posible el entrenamiento de los LLM, la red de atención es indispensable puesto que integra en el modelo una forma de aprender y utilizar asociaciones entre palabras y conceptos en un tiempo razonable. Además no solo se trata de una red de atención sino que son varias que operan al mismo tiempo en paralelo por lo que el proceso se ejecuta en múltiples GPUs. De esta manera, el crecimiento de los LLM ha sido gracias a las redes de atención pues le permitir procesar gran cantidad de datos.
No obstante, el crecimiento de los LLM no es infinito pues los insumos son caros (datos, poder de cómputo, electricidad, mano de obra) y los resultados del entrenamiento no crecen tan rápido como si lo hacen los insumos. En este sentido, la cantidad de datos de entrenamiento disponibles obtenidos de Common Crawl también es finita y si se quiere acceder a más datos implica incrementar los costos para ingresar a otras fuentes como la corporativas o de dispositivos personales (dato crucial 12).
También conseguir un GPU con mayor rendimiento que el de la década de 2010 será difícil por lo que se estima que el entrenamiento de los LLM cada vez será más costoso. Es decir, puede que las computadoras se hagan más robustas con el tiempo (aunque las mejoras también residen en la capacidad de los chips que están sujetos a las restricciones de la ley de Moore y la reducción de circuitos), pero si la GPU no se hace más potente, procesar grandes cantidades de datos será imposible para un equipo de cómputo (datos cruciales 13 y 14).
Aunado a eso, es probable que salten los problemas legales a causa de la violación a los derechos de autor por utilizar información protegida. En este sentido, OpenAI espera que su LLM esté protegido por la ley de “uso justo” que permite el uso limitado de material protegido por derechos de autor con fines “transformadores” (dato crucial 15).
Un dispositivo importante
Finalmente, no se habla de que una hipotética bancarrota de OpenAI a causa de una demanda o las limitaciones económicas hagan que los LLM desaparezcan. Por el contrario, está fue una innovación que nació de un proyecto de código abierto y a raíz de eso la aparición de otros modelos han surgido en manos de diferentes empresas. Después de todo, los datos y las herramientas siguen estando disponibles. Sin embargo, los riesgos existenciales continuarán en la medida que siga avanzando esta tecnología.
1) Entre los atributos de GPT-4, la red neuronal artificial que impulsa a ChatGPT, se citan la aprobación de los exámenes de admisión a las carreras de derecho y medicina en Estados Unidos, la generación de canciones, poemas y ensayos.
2) En 2016 Lee Sedol, uno de los mejores jugadores del antiguo juego de mesa chino Go, se enfrentó contra el software basado en redes neuronales de Google llamado AlphaGo. El resultado final fue a favor de AlphaGo.
3) El diccionario de GPT-3 contiene detalles de 50 257 tokens.
4) GPT-3 es capaz de procesar un máximo de 2 048 tokens a la vez (equivalente aproximado a un artículo de The Economist) mientras que GPT-4 puede manejar entradas de hasta 32 mil tokens (equivalente a la extensión de una novela).
5) Jason Wei, investigador de OpenAI, ha contabilizado 137 capacidades emergentes en diferentes LLMs.
6) El modelo GPT-4 aprobó en el percentil 90 el Examen uniforme del Colegio de abogados de Estados Unidos, diseñado para evaluar las aptitudes del jurisperito antes de que obtenga su licencia. El modelo GPT-3.5 (un modelo entre GPT-3 y GPT-4) no lo aprobó.
7) Jonas Degrave, ingeniero del laboratorio de inteligencia artificial (IA) Deepmind (propiedad de Alphabet), ha demostrado que se puede convencer a ChatGPT para que actué como la terminal de línea de comandos de una computadora emulando la compilación y ejecución de programas con precisión.
8) Los detalles sobre la construcción y la función de GPT-3 fueron publicados en 2020 por OpenAI en un artÍculo llamado Languaje Models are Few-Shot Learners. No obstante, los detalles sobre GPT-4 aún son privados.
9) GPT-3 se entrenó en varias fuentes de datos aunque la mayor parte de la información proviene del internet entre 2016 y 2019 tomadas de una base de datos llamada Common Crawl. Existe una gran cantidad de texto basura en internet por lo que los 45 terabytes iniciales se filtraron utilizando un modelos de aprendizaje diferente para seleccionar solo texto de 570 gigabytes; texto de alta calidad que podría caber en una computadora portátil moderna.
10) AlexNet fue una red neuronal que reavivó la emoción por el procesamiento de imágenes en 2010. Se entrenó en un conjunto de datos de 1.2 millones de imágenes etiquetadas para dar un total de 126 gigabytes (se estima que comparado con GPT-4, sería una décima parte del tamaño de su conjunto de datos).
11) La gráfica 1 describe el poder de cómputo utilizado por diferentes motores de entrenamiento de IA del periodo 1950 a 2023. A principios de 2023 GPT-4 obtuvo el mejor puntaje sobre GPT-3, Stable Diffusion y Transformer.
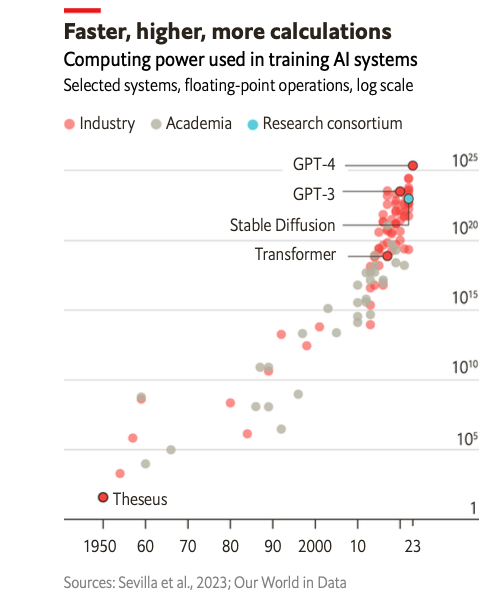
12) El entrenamiento de GPT-3 utilizó 1.3 gigavatios-hora de electricidad (equivalente a alimentar 121 hogares en Estados Unidos durante un año) y le costó a OpenAI cerca de 4.6 millones de dólares (mdd). GPT-4, un modelo más grande, se estima que habrá costado muchísimo más para entrenar (en los límites de 100 mdd).
13) De acuerdo con Sam Altman, directo ejecutivo de OpenAI, el entrenamiento de los LLM parece haber llegado a su punto de inflexión. El 13 de abril de 2023 compartió para el Instituto Tecnológico de Massachusetts que probablemente era el final para el crecimiento de estos grandes modelos aunque serían mejorados de otras maneras.
14) Un artículo publicado en octubre de 2022 concluyó que el stock de datos lingüísticos de alta calidad se agotará pronto (quizás antes de 2026).
15) Stability ai, una empresa que utiliza IA generativa llamada Stable Diffusion para generar imágenes, fue demandada por Getty Images (agencia de fotografía) por utilizar material protegido con marca de agua. Cabe destacar que Stable Diffusion utiliza la misma base de datos de entrenamiento que GPT-3 y GPT-4, Common Crawl.
Al final de la nota de The Economist se plantea un problema que merece otro análisis profundo. Puede que OpenAI no tenga la capacidad tecnológica ni económica para hacer crecer más su motor GPT. No obstante, como esta tecnología ya se difundió es bastante fácil para las grandes firmas tecnológicas continuar desarrollando los grandes modelos de lenguaje; sobra decir que cuentan con los recursos económicos, científicos y técnicos. Esto se traduce en una mayor concentración del poder monopólico de estas empresas lo que conllevaría no solo a una mercantilización de datos sin precedentes sino a un mercado más difícil de acceder y que pasa por desapercibido debido a la tendencia a romantizar y fanatizar a las grandes firmas tecnológicas normalmente por parte de las generaciones más jóvenes.
Otra arista sobre el desarrollo de los LLM es que actores asiáticos, en particular China, tienen acceso a ingentes datos para entrenamiento de los modelos, en relación con sus regímenes autoritarios.
Y una cuestión que queda por establecer es cómo tales capacidades que conciernen actividades cotidianas pueden devenir riesgos existenciales. Es evidente en términos de informaciones incorrectas y/o falsas que pueden generar crisis financieras de graves consecuencias, pero esa relación es menos evidente respecto del manejo de armamentos y otras posibilidades de riesgos catastróficos...
{kind=link}