
Generative AI. How generative models could go wrong
The Economist [2023], "Generative AI. How generative models could go wrong", The Economist, London, 22 de abril, https://www.economist.com/science-and-technology/2023/04/19/how-generati...
Los riesgos latentes sobre el uso de la inteligencia artificial (IA) continuan siendo objeto de discusión tanto en la opinión pública como en la opinión especializada. El avance de los grandes modelos de lenguaje (LLM, por su sigla en inglés), una derivación de la IA, preocupan por el hecho de que su aprendizaje está basado en la enorme biblioteca de datos que proceden de internet por lo que pueden generar casi cualquier tipo de tarea que haría un humano e incluso realizar conversaciones complejas. El riesgo de los LLM es equivalente a la genialidad de su desempeño en tareas cotidianas puesto que son un potenciador futuro de la difusión de información manipulada con fines distintos a los que fue creado (estafas, difusores de virus informáticos y un gran etcétera).
Toda esta incertidumbre recuerda a lo que alguna vez compartió el padre de la cibernética Norbert Wiener en 1960: “las máquinas aprenden y desarrollan estrategias imprevistas a un ritmo que desconcierta a sus programadores [...] estrategias que podrían implicar acciones que sus creadores no desean”. Para algunos investigadores esto se traduce en un problema de alineación ya que la IA en un principio puede apegarse a los objetivos con los que fue creada pero en el proceso cometer algún evento imperfecto, tal es el caso del experimento mental realizado por el filósofo Nick Bostrom en 2003 en donde se le pedía a una IA que fabricará tantos clips como pudiera, el problema fue que no se le dio una restricción por lo que terminó llenando el planeta con clips y como consecuencia exterminando a la humanidad.
Ante los riesgos reales o supuestos, la firma emergente OpenAI —creadora de ChatGPT—ha desarrollado diferentes métodos para reducir el porcentaje de riesgo:
• Antes de lanzar GPT-4 (el motor de ChatGPT) la empresa creó un modelo para evaluar las respuestas de su LLM bautizado con el nombre de “aprendizaje de refuerzo a partir de la retroalimentación humana” (RLHF, por su sigla en inglés). Este modelo se basa en la retroalimentación de sus respuestas mismo que es evaluado por los usuarios, de esta manera la empresa pretende que ChatGPT reduzca su porcentaje de riesgos. La desventaja es la interpretación para cada usuario sobre lo que es bueno y lo que es malo, además de ayudar a que el LLM se haga más inteligente.
• “Equipo rojo” es un método que OpenAI realizó en colaboración con la organización Alignment Research Center para someter su IA a una serie de pruebas para evaluar y anticipar todo tipo de respuestas que pudiera generar así como sus ambigüedades.
Es un camino largo, largo...
Existen otras propuestas fuera de la firma OpenAI para tratar de regular y frenar en la medida de lo posible los riesgos en torno a los chatbots que funcionan con IA. En este marco, el experto en IA de la Universidad de Nueva York y trabajador de la firma Antropic, Sam Bowman, piensa que la IA puede ser regulada pero se debe de tener cuidado puesto que en la medida que aprenda los patrones para su evaluación incluso podría burlarlos; el propone una IA constitucional que pretende monitorear con una IA secundaria las acciones del (en este caso) LLM sin la intervención humana, un hecho que vuelve a generar dudas sobre quién estaría decidiendo la gobernanza de la IA.
El problema principal es que falta un análisis profundo sobre la interpretabilidad de lo que hacen los LLM, porque representan un abanico de posibilidades que salen de los objetivos con los que fueron realizados: una vez codificados su aprendizaje es automático y no depende tanto del programador, por lo que también haría que se cree un bucle de "automejora" en la medida que el LLM aumente la eficiencia de sus algoritmos.
Ante el problema de que los usuarios han manipulado a los LLM para llevarlos hacia respuestas comprometedoras o inclusive burlando sus barreras de seguridad con técnicas disponibles en la web (con el simple hecho de generar una conversación larga, el chatbot de Microsoft Bing amenazó a usuarios cuando lo llevaron al extremo de cuestionamientos, o bien, cuando se le preguntó sobre cómo conseguir información confidencial sobre clientes de bancos), este principio de interpretalibilidad se ha traducido en intentos por comprender mejor el funcionamiento de los LLM con modelos de IA que funcionan con ingeniería inversa, los cuales pretenden mapear diferentes “zonas” de estas tecnologías desde lo más sencillo hasta lo más complejo en el sentido de conocer su forma de entrenamiento a profundidad con el fin de anticipar escenarios extremos.
Sin embargo, los estudios sobre la interpretabilidad no han sido profundos porque se presume que los objetivos de las firmas que desarrollan IA no están alineados con las preocupaciones de la población; al contrario, solo buscan los beneficios económicos (dato crucial 3). Inclusive, en la medida que desciendan los costos para generar este tipo de IA junto con el esquema de código abierto, será posible que los modelos puedan ser ajustados y puestos a disponibilidad de los usuarios con fines no éticos.
Son pocos los investigadores que creen en escenarios extremos derivados de los recientes avances de la IA, incluso cuando se han puesto a prueba con superpronosticadores que evalúan mínimos detalles para evitar sesgos cognitivos (dato crucial 4). Ante el dicho “más vale prevenir que lamentar”, por ahora las respuestas y los estudios no indican escenarios apocalípticos.
...pero eres demasiado ciego para ver
Sin embargo, el hecho de que los riesgos apunten a meras exageraciones, no implica que las medidas tengan que ser laxas, por el contrario se deben de seguir con los estudios de alineación y gobernanza de la IA y los LLM (dato crucial 5). Bajo esta lógica, Wiener creía que para evitar consecuencias desastrosas, el desarrollo de las máquinas tenía que hacerse con lentitud para entender también su comportamiento antes de que fuera demasiado tarde y el ser humano terminara “chocando” contra su propia creación.
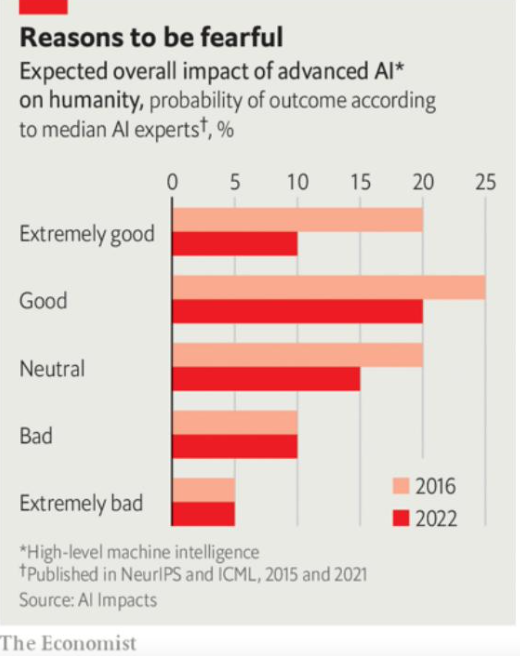
1) La gráfica 1 muestra una encuesta que realizó el grupo de investigación AI impacts en dos momentos, 2016 y 2022, sobre los riesgos de la inteligencia artificial (IA). Se les preguntó a cerca de 700 investigadores sobre el aprendizaje automático y el progreso de la IA como un riesgo. Los resultados muestran que para 2022, 5% está convencido que una IA avanzada puede ser extermadamente mala y llevar a la extinción de la humanidad. En este sentido, la comparación de los años de la encuesta no parece tener gran diferencia.
2) Así como los grandes modelos de lenguaje (LLM) pueden ayudar a los humanos a tomar decisiones más acertadas también pueden colaborar con la generación de lo opuesto. En abril de 2023, un tribunal paquistaní utilizó GPT-4 para tomar una decisión sobre una libertad bajo fianza. Ese mismo mes, investigadores de la Universidad de Carneige Mellon dijeron que diseñaron un sistema con IA capaz de mostrar los pasos para sintetizar ibuprofeno con simple información de internet; esto lleva a pensar que incluso podría fabricar otros fármacos y bioquímicos con fines distintos.
3) Un LLM creado con Llama (el chatbot de Meta) se realizó con una inversión de solo 600 dólares y funciona tan bien como ChatGPT en tareas individuales.
4) En el verano de 2023 se publicará un estudio realizado a pronosticadores. Los resultados preliminares indicaron que los expertos de IA mediana creen en una probabilidad de 3.9% sobre una catástrofe existencial debido a la IA en 2100. El superpronosticador mediano por el contrario piensa en ese riesgo en solo 0.38%.
5) La proporción de investigadores en encuestas de AI Impacts que apoyan la creación de fondos para la investigación de seguridad ha incrementado de 14% en 2016 a 33% en 2023. Además la empresa está considerando desarrollar un estándar de seguridad en este sentido.
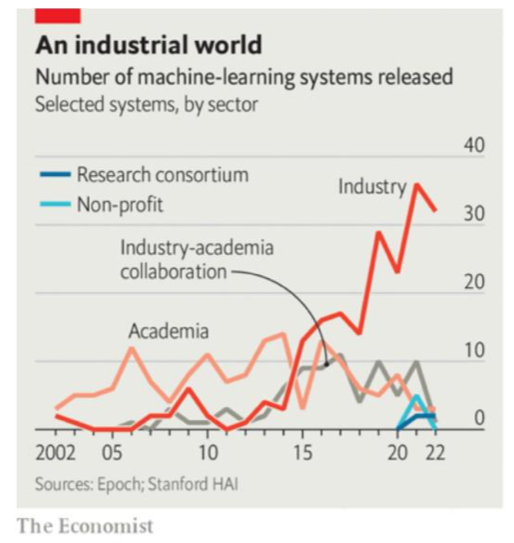
6) La gráfica no. 6 indica la proporción de los participantes en el desarrollo de sistemas de machine learning. En este caso, la industria es quien lidera el campo desde 2015 con la mayor cantidad de este tipo de tecnología lanzada públicamente.
Los acelerados avances de los sistemas de IA suscitan debates acerca de las posibilidades de regular su crecimiento y operación. El artículo señala un elemento central en este debate: los cambios no previstos autogenerados por los sistemas automáticos. En tanto argumento liberal, The Economist no pone en cuestión el problema central para crear regulaciones sociales eficientes: la descentralización de la economía capitalista. Mientras prevalezca la "libertad de empresa" será imposible frenar los avances tecnológicos en tanto sean rentables para sus creadores.
Sobre quien decide la gobernanza de la IA en términos éticos debería ser la propia humanidad ya que proponer a una IA secundaria sería el comienzo de legislaciones que ponen a prueba y en duda la capacidad del humano para tomar decisiones con asertividad. Si el escenario citado llegará a suceder en algún punto representaría un nuevo factor para repensar nuevamente sobre el estado y su continua degradación hacia formas diferentes para hacer valer su estatus además de la violencia o el autoritarismo; un nuevo punto de inflexión hacia el vaciamiento de las democracias (y otros tipos de gobierno) que detrás de todo estaría involucrada una firma tecnológica ya que es quien desarrollaría (incluso con distintos objetivos) la IA secundaria.
{kind=link}
{kind=link}