
Infrastructure. Should data be crunched at the centre or at the edge?
The Economist [2020], "Infrastructure. Should data be crunched at the centre or at the edge?", The Economist, London, 20 de febrero, https://www.economist.com/special-report/2020/02/20/should-data-be-crunc...
Amazon Web Services (AWS) representa un modelo centralizado de la nube donde todos los datos recolectados son analizados en lugares denominados centros de bigdata. SWIM.AI es un ejemplo de lo que se llama "cómputo en el borde" [edge computing]: es el procesamiento de datos en tiempo real lo más cercano posible al lugar donde es recolectada la información. Para The Economist el próximo desarrollo de la infraestructura para la economía de la información [data economy] se expandirá enmedio de estos dos. Para cada estación de centro de datos se necesita una gran variedad de redes de cables y conexiones que sirvan para recolectar información de cada rincón del mundo. Actualmente los bits siguen siendo generados usualmente por el clickeo humano en sitios web o pinchando el celular; pero en los siguientes años serán más los datos generados por la conectividad de todos los dispositivos mediante lo que se llama el "internet de las cosas" (Dato Crucial 1). Estos dispositivos, además de servir como sensores, tendrán la capacidad de intervenir y actuar en el mundo real en el que están inmersos. Esto también se deberá al nuevo soporte de la conexión 5G (Dato Crucial 2 y 3).
Cada vez es más la información digital que deja el dispositivo móvil donde originalmente fue creada para fluir hacia los grandes centros de cómputo operados por corporaciones como AWS, Microsoft Azure, Alibaba Cloud y Google Cloud. La centralización y la dimensión de estas grandes corporaciones es impresionante (Dato Crucial 4 y 5). Además, sus estrategias apuntan no solo a conservar su tamaño actual sino a incrementarlo (Dato Crucial 6). En el fondo, esto se favorece por los efectos en red que consiste en que los datos atraen más datos, ya que son más rentables en mayores dimensiones, un fenómeno llamado “gravedad de los datos” [data gravity]. Una vez que una empresa almacena datos importantes en la nube serán más las aplicaciones de sus negocios que se trasladarán también a la nube, lo que generará a su vez más ganancias a los proveedores de cómputo en la nube. Entre los servicios de estas grandes plataformas se encuentra disponible una amplia gama de opciones para que los usuarios procesen y analicen [minen] su propia información de acuerdo a sus necesidades
Sin embargo, dicha transición a la nube deviene en costos. Primero, están las tarifas que pagan las empresas cuando quieren trasladar su información hacia otros proveedores de nubes. Más aún, almacenar datos en grandes centros podría también incrementar los costos ambientales, ya que el envío de datos a una locación central implica consumo energético; además una vez almacenada la información, se vuelve tentador analizarla (Dato Crucial 7).
Por otra parte, lo que también vemos es un contra-movimiento hacia el "computo en el borde" en los sitios donde la información es recolectada. No sólo los servidores en los grandes centros de datos se vuelven más fuertes, sino también los centros locales, lo que permite que los datos sean analizados más cerca de su fuente de origen. Incluso los softwares actuales permiten desplazar el poder de cómputo a dónde pueda operar mejor, sea en los propios dispositivos de “internet de las cosas” o cerca de ellos.
El debate gira entorno que tan lejos podrá llegar este contra-movimiento que descentraliza el poder de cómputo de los grandes servidores de la nube.
1. Ericsson, un fabricante de equipos de red, pronostica que el número de dispositivos de “internet de las cosas” alcanzará los 25 000 millones en 2025, frente a los 11 000 millones en 2019.
2. La próxima generación de tecnología móvil 5G está diseñada para soportar conexiones de 1 millón por kilómetro cuadrado, lo que significa que sólo en Manhattan podría haber 60 millones de conexiones.
3. Ericsson estima que las redes móviles llevarán 160 exabytes de datos a nivel mundial cada mes para 2025, cuatro veces la cantidad actual.
4. De acuerdo con Bill Vass, director al mando del departamento de almacenamiento de AWS, la corporación AWS es 14 veces más grande que su rival más próximo, Azure.
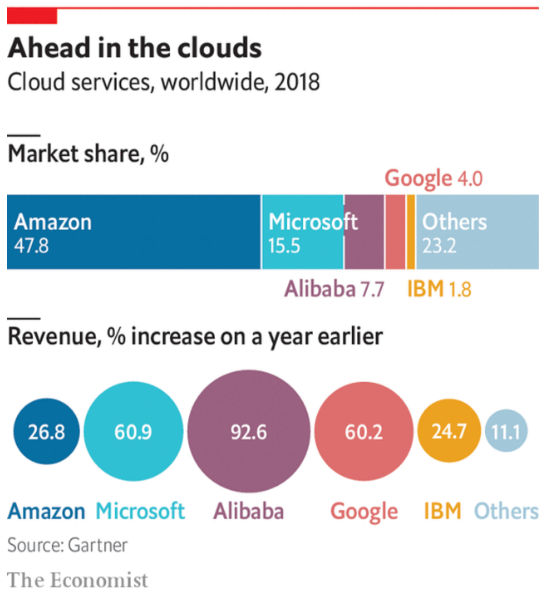
5. Gráfica. Los principales servidores en la nube por su cuota de mercado, 2018: Amazon (47.8%), Microsoft (15.5%), Alibaba (7.7%), Google (4%), IBM (1.8%) y otros (23.2%).
Los principales servidores en la nube por la tasa de crecimiento anual de sus ganancias, 2018: Alibaba (92.6%), Microsoft (60.9%), Google (60.2%), Amazon (26.8%), IBM (24.7%) y otros (11.1%).
6. AWS ofrece al menos 14 diversas formas de introducir datos en su nube, incluidos varios servicios para hacerlo a través de internet, pero también métodos en desconexión, como camiones con almacenamiento digital que pueden contener hasta 100 petabytes para transportar datos.
7. De acuerdo a OpenAI, una startup, el poder de computo en el borde [cutting-edge] utilizado en proyectos de Inteligencia Artificial comenzó a explotar en 2012. Antes de eso era vigente la Ley de Moore que sostiene que la potencia de procesamiento de los chips se duplica aproximadamente cada dos años; sin embargo, desde entonces, la demanda se duplica cada 3.4 meses.
La creciente concentración del poder de cómputo bajo unas cuantas grandes plataformas digitales con escala global pone a su disposición no sólo la concentración de enormes ganancias sino al mismo tiempo el control y la disposición de masivas cantidades de información así como su procesamiento, su uso y el desarrollo de nuevas tecnologías.
{kind=link}