
For AI, data are harder to come by than you think
The Economist [2020], "For AI, data are harder to come by than you think", The Economist, London, 13 de junio, https://www.economist.com/technology-quarterly/2020/06/11/for-ai-data-ar...
Para The Economist, las tiendas Amazon Go son lugares impresionantes. La primera de estas tiendas fue abierta en Seattle en 2018. En ellas, por medio de una la aplicación, los clientes pueden tomar los productos que quieran comprar y salir de la tienda, sin necesidad de pasar por una caja de cobro. El sistema funciona con la ayuda de muchos sensores, pero principalmente con la ayuda de cámaras conectadas a un sistema de inteligencia artificial (IA en adelante) que rastrea los productos tomados de los estantes. Una vez que los clientes salen de la tienda, su compra es calculada y cobrada de forma automática.
Sin embargo, hacer esto en una tienda llena de gente no es nada fácil. El sistema tiene que lidiar con clientes que desaparecen de la vista detrás de otros, reconocer clientes individuales, así como grupos de amigos, grupos familiares y debe hacer todo esto en tiempo real y con un nivel alto de precisión. Entrenar al sistema requiere de una gran cantidad de “datos de capacitación”, en este caso, en forma de vídeos de clientes buscando productos por los pasillos de la tienda, tomándolos y luego poniéndolos de vuelta en el estante, por ejemplo. Para otras tareas estandarizadas, como el reconocimiento de imágenes, los desarrolladores de IA pueden usar archivos de datos para entrenamiento público, cada uno con miles de fotos, pero no existen este tipo de archivos de datos con personas recorriendo los pasillos de las tiendas.
Si bien, algunos de estos datos de entrenamiento fueron generados por los propios empleados de Amazon, que fueron utilizados para desarrollar versiones de prueba de las tiendas, para que el sistema funcionara correctamente en el mundo real necesitaba entrenarse en todas las formas en que las personas pueden tomar un producto del estante y luego elegirlo, o ponerlo de vuelta inmediatamente o después de un tiempo.
Teóricamente, el mundo está lleno de datos, el alimento primordial de la IA moderna. De acuerdo a algunos investigadores, en 2018 en el mundo se generaron 33 zettabytes de datos. A pesar de ello, los datos son de los puntos más conflictivos de cualquier proyecto de IA. Tal como en el caso de las tiendas Amazon Go, los datos pueden no existir, o podrían ser propiedad de la competencia. Incluso cuando los datos pueden conseguirse, estos podrían no ser del todo adecuados para alimentar al sistema.
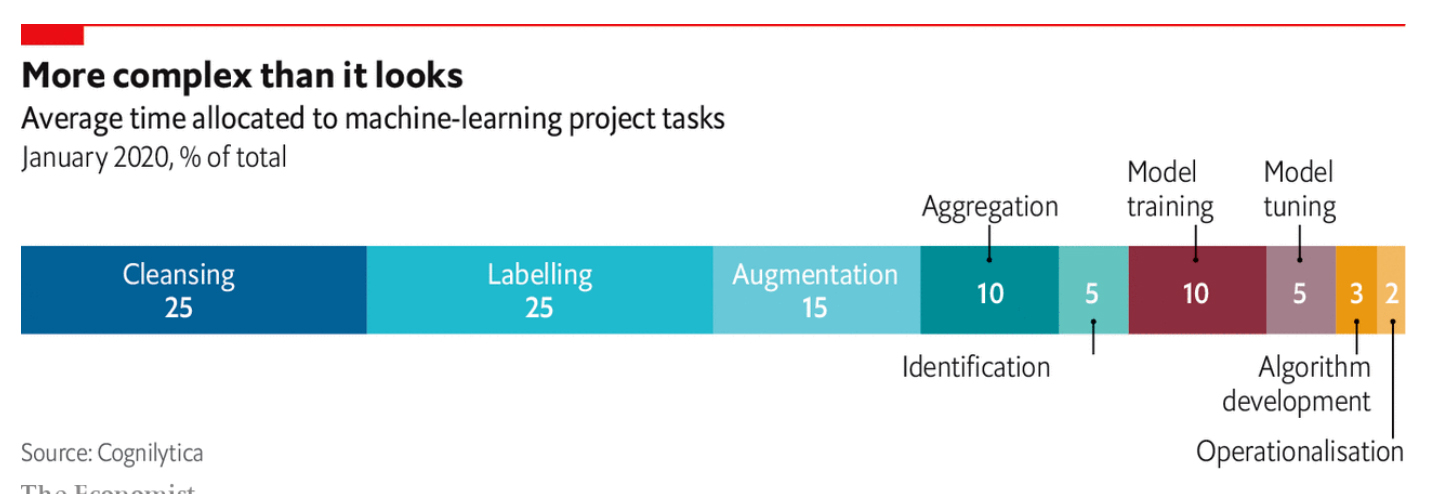
Según Cognilytica, una consultora especializada en IA, transformar los datos “crudos” en datos aptos para el sistema consume 80% del tiempo de los proyectos de IA. Para entrenar un sistema de aprendizaje automático se requiere del etiquetado de ejemplos, generalmente hecho por seres humanos. Generalmente, las grandes compañías de tecnología hacen este trabajo de forma interna, mientras que las compañías que carecen de los recursos o la experiencia requerida recurren a contratistas externos para realizar estas tareas. La compañía china MBH, por ejemplo, emplea a más de 300 000 personas para etiquetar imágenes de rostros, o escenas callejeras o radiografías médicas, para que estas puedan ser procesadas por las computadoras. Mechanical Turk, una subdivisión de Amazon, conecta a empresas con un ejército de trabajadores eventuales a quienes se le paga a destajo para realizar estas tareas.
De acuerdo con esta consultora, el mercado de los datos preparados por terceros alcanzó los 1 500 millones de dólares en 2019 y se estima que podría alcanzar los 3 500 millones para 2024, mientras que las empresas gastaron 1 700 millones de dólares en el negocio de etiquetado de datos en 2019, y para 2024 se espera que alcance los 4 100 millones de dólares. No es necesario que el etiquetado de datos lo lleven a cabo expertos. Los diagnósticos médicos, por ejemplo, pueden ser hechos por etiquetadores sin conocimiento técnico en medicina; basta con ser entrenados en reconocer fracturas y tumores. Sin embargo, siempre la experiencia en estos campos es vital.
Según The Economist, los datos en sí mismos pueden contener trampas. Los sistemas de aprendizaje automático correlacionan las entradas (inputs) con las salidas (outputs) de forma irreflexiva, sin entender el contexto. En 1969, un gurú de la programación, Donald Knuth, advirtió que las computadoras “hacen exactamente lo que se les ordena, ni más, ni menos”. La historia del aprendizaje automático está lleno de ejemplos de esto. En 2018, investigadores de la red de hospitales Mount Sinai, en Nueva York, encontraron que un sistema para detectar neumonía en radiografías de tórax, fue menos competente cuando se usó en otros hospitales diferentes a aquellos en donde fue entrenado. Los investigadores descubrieron que el sistema había podido averiguar de qué hospital provenía la radiografía. Dado que un hospital en su set de entrenamiento tenía una tasa basal de neumonía mucho más alta que los otros, esta información por sí misma fue suficiente para aumentar la precisión de todo el sistema. Los investigadores llamaron a esto “trampa” debido a que el sistema falló cuando recibió datos de hospitales que no conocía.
Diferente tipo de raza
Otra fuente de problemas son los sesgos. El Instituto Nacional de Estándares y Tecnología de Estados Unidos probó el año pasado cerca de 200 algoritmos de reconocimiento facial y encontró que muchos eran considerablemente menos precisos para identificar rostros negros que rostros blancas. El problema puede reflejar la preponderancia de rostros blancos en sus datos de entrenamiento. También el año pasado, un estudio realizado por IBM encontró que cerca de 80% de los rostros en tres paquetes de datos de entrenamiento consistían en rostros con piel clara.
Si bien, estas deficiencias, en teoría, son fáciles de arreglar (IBM ha ofrecido de forma abierta un set de datos más representativo para quien quiera usarlo), otras fuentes de sesgos pueden ser más difíciles de eliminar. En 2017, Amazon abandonó un programa de reclutamiento, diseñado para buscar a través de miles de currícula a los candidatos más indicados para la empresa, cuando se descubrió que el sistema favorecía al género masculino. Posteriormente se reveló un problema circular autorreforzante: el sistema había sido entrenado con currícula de solicitantes que habían conseguido un lugar en la empresa, pero debido a que la mayoría de los empleados eran varones, el sistema entrenado en datos históricos asocia la masculinidad como un fuerte elemento de idoneidad en los candidatos.
Para muchos expertos, aunque se puede tratar de evitar tales inferencias, los algoritmos pueden llegar a ser más astutos que sus programadores al usar otros indicadores para reconstruir la información prohibida, desde pasatiempos y anteriores trabajos, hasta códigos de área en números telefónicos, que podría contener pistas del sexo, la edad o la etnicidad del solicitante.
Una alternativa, frente a las dificultades que plantean los datos del mundo real, es inventar datos propios. Esto fue lo que hizo Amazon para calibrar sus tiendas GO: utilizó software de gráficos para crear compradores virtuales. Los clientes virtuales fueron usados para entrenar a las máquinas en situaciones difíciles e inusuales que no se habían presentado en los datos reales de entrenamiento, pero podrían suceder en el mundo real. También, las empresas de automóviles autónomos hacen entrenamiento con simulaciones de alta fidelidad de la realidad. En un artículo publicado en 2018, Nvidia, un fabricante de microprocesadores, describió un método para crear rápidamente datos sintéticos de entrenamiento para autos autónomos, y concluyó que los algoritmos resultantes funcionan mejor que aquellos entrenados con datos reales.
Otro de los atractivos de los datos sintéticos es la privacidad. Muchas empresas que esperan aplicar la IA en medicina o en finanzas deben lidiar con leyes estrictas que protegen la privacidad de los datos. Anonimizar estos datos puede ser bastante difícil, un problema del que no necesitan preocuparse los sistemas entrenados con datos sintéticos.
La clave está en que estas simulaciones sean cercanas a la realidad, como para que sus lecciones sean productivas. Si bien, esto es fácil, en el caso de algunos problemas bien definidos, como la detección de fraude o calificaciones crediticias, donde los datos sintéticos pueden ser creados agregando ruido estadístico a los números reales; pero entre más complicado se vuelve un problema, cuanto más difícil es garantizar que las lecciones extraídas de los datos virtuales se traduzcan de manera útil al mundo real.
Según The Economist, aunque se espera que todas estas complicaciones sean temporales y que una vez capacitados estos modelos de aprendizaje automático puedan hacerse cargo de millones de decisiones de forma automatizada, muchos modelos de IA están sujetos a los cambios en el funcionamiento del mundo, es decir, se vuelven menos precisos en la medida en que pasa el tiempo. El comportamiento del cliente cambia, el lenguaje evoluciona, las regulaciones sobre lo que las empresas pueden hacer también cambian. Estos cambios pueden ocurrir de la noche a la mañana. Muchos de los sistemas de reconocimiento facial están luchando contra las mascarillas faciales que está usando la gente para protegerse del contagio de Covid-19, por ejemplo. De la misma forma, los sistemas logísticos automatizados han necesitado ayuda humana para lidiar con la repentina demanda de papel higiénico y otros productos. Los cambios en el mundo significan que es necesario alimentar a las computadoras con más datos y un ciclo interminable de reentrenamiento, advierten los expertos.
En el artículo de The Economist advierte uno de los límites del uso de la inteligencia artificial que se ha comenzado a apreciar con más claridad a partir de la crisis de Covid-19, aunque otros, como el de los sesgos ya eran ampliamente conocidos, se trata del entrenamiento de los algoritmos, que para llevarse a cabo necesita de grandes cantidades de trabajo humano y de la existencia de datos de buena calidad, y necesita de estos de forma constante. Si bien, estos contratiempos no representan por el momento la pérdida de las altas expectativas que se tenían de esta tecnología, sí representa uno de los primeros límites serios, junto a los distintos tipos de sesgos en los datos, a los que se enfrenta esta tecnología.
{kind=link}
{kind=link}