
Should We Treat Data as Labor? Moving Beyond 'Free'
Arrieta, Imanol, et. al. [2018], "Should We Treat Data as Labor? Moving Beyond 'Free'”, AEA Papers and Proceedings, 108: 38-42, https://poseidon01.ssrn.com/delivery.php?ID=0400880200030140640810710900...
Imanol Arrieta Ibarra está adscrito al Departamento de Ciencias de la Gestión e Ingeniería de la Universidad de Stanford.
Leonard Goff adscrito al Departamento de Economía de la Universidad de Columbia.
Diego Jiménez Hernández adscrito al Departamento de Economía de la Universidad de Stanford.
Jaron Lanier es Director de Tecnología en Microsoft Corporation.
E. Glen Weyl miembro del equipo de Microsoft Research.
La propuesta del texto es abordar los datos digitales como un mercado laboral, específicamente como un “mercado radical” [radical market]. Para los autores, los mercados radicales son un potencial emancipatorio por su capacidad para crear o fortalecer mercados donde los usuarios no son remunerados por la información con la que contribuyen a los servicios digitales. De fondo el tema está en que la actual cultura de “gratuidad” en-línea ocasiona problemas sociales de desigualdad, estancamiento y conflictos socio-políticos. Mientras que, por un lado, la información gratuita de los servicios digitales son un negocio rentable; por el otro, la falta de incentivos socava los principios de mercado para su evaluación, además distorsiona la distribución de los retornos financieros y detiene el desarrollo de los usuarios para llegar a ser "ciudadanos digitales de primera clase".
I. El alto costo de los datos gratuitos
La economía digital es la fuente líder de innovación en nuestros días, a pesar de sus beneficios, fenómenos como la ansiedad y la violencia han aumentado. La cuestión más preocupante está en el empleo y la distribución del ingreso. Los economistas indican que en el pasado las disrupciones tecnológicas al paso que provocaban cambios en el empleo también generaban una creciente participación del trabajo en el ingreso. No obstante, hoy en día la cada vez menor participación del trabajo contradice la estabilidad universal. Un indicador de esto está en el número de empleos generados por las empresas tecnológicas líderes cuyas capitalizaciones bursátiles son altísimas en comparación con otras grandes empresas, pero con menores contrataciones laborales.
La falta de pagos a los usuarios por su información podría frenar las contribuciones de la Inteligencia Artificial (IA) al crecimiento de la productividad. Esto por el papel que juegan los datos en esta tecnología. La primera generación de sistemas de IA fracasaron en lograr sus objetivos debido a su alta dependencia en la codificación especializada realizada por ingenieros. Actualmente la nueva generación de IA utiliza métodos estadísticos llamados "aprendizaje automático" [machine learning] para adaptarse a los patrones del comportamiento humano en operaciones similares (big data).
En términos generales el modelo de información gratuita ha hecho que la productividad relacionada a los datos no beneficie directamente a los trabajadores que la hacen posible. Se explica que los datos pasan por un proceso de tareas ejecutadas por diversos trabajadores pero sus rendimientos en la productividad pasan a ser patentados por las empresas, las cuales venden a otras empresas interesadas.
De hecho, muchos sistemas de IA dependen de la participación activa de los humanos para generar datos relevantes. Esto empieza cuando con el permiso concedido por parte de los usuarios a las empresas para acceder a sus datos creados en el curso de sus actividades cotidianas. Estos sistemas generalmente no retribuyen a quienes tienen la mayor experiencia. De esta manera el modelo gratuito actúa como un lastre para el crecimiento de la productividad que continúa rezagado en todo el mundo, pese a al gran potencial de la IA. La expulsión de los trabajadores va en aumento al mismo tiempo que crecen las interacciones digitales como redes sociales y videojuegos; y dado que estas actividades están del lado del consumo más que como producción, se cree que estas crecientes vidas virtuales socavan la dignidad laboral.
II. ¿Capital o trabajo?
Para los autores el aspecto central de la economía política de los datos está relacionado con un enfoque específico de tratar los "Datos como Capital" (DcD). En contraposición los autores proponen un enfoque para tratar los "Datos como Trabajo" (DcT). Esta distinción no es irrelevante y de hecho la actitud social hacia los activos en estas categorías han jugado un papel importante en la historia. La Tabla 1 contrasta ambos paradigmas: “Datos como capital (DcC)” vs “Datos como trabajo (DcT)”.
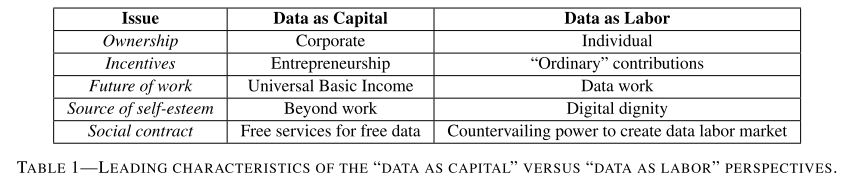
1. DcC trata a los datos como un extracto natural proveniente del consumo, que es recolectado por las corporaciones. La DcT los concibe como posesiones de los usuarios que deberían beneficiar principalmente a sus propietarios.
2. DcC canaliza los pagos de los datos a las compañías y plataformas de IA para fomentar el emprendimiento y la innovación, mientras que DcT los encausa a usuarios individuales para fomentar una mayor calidad y cantidad de datos.
3. DcC desarrolla la IA para el desplazamiento de trabajadores, esto con el apoyo de un "ingreso básico universal" y reservando las esferas de trabajo solo para atender las fallas de la IA. La DcT concibe al aprendizaje automatizado como una tecnología de producción más, que debería mejorar la productividad laboral y crear una nueva clase de "trabajadores de datos".
4. DcC alienta a que los trabajadores encuentren la dignidad en el ocio o en las interacciones humanas fuera de la economía digital, en contraste DcT promueve al trabajo de datos como una nueva fuente de "dignidad digital".
5. DcC plantea un contrato social virtual en los servicios otorgados gratuitamente a cambio de una vigilancia permanente. Mientras DcT concibe la necesidad de crear instituciones a gran escala que regulen la capacidad de las plataformas de datos en el uso de su poder de monopsonio sobre los proveedores de datos y garanticen un mercado justo y dinámico para los trabajadores de datos.
Los propios autores reconocen la simplificación del ejercicio comparativo entre ambos modelos pues en los hechos ambos funcionan una complejidad mucho mayor. De hecho se puede considerar que la función de producción de los datos y los sistemas de IA requiere de varios factores de producción: un flujo constante de datos, capital (ej. poder de computo), trabajo calificado (ej. programadores), talento empresarial y el factor “tierra” (ej. rentas de los efectos en red). La participación óptima de cada factor depende de detalles aún inconmensurables. Hay que considerar que los datos en sí mismos no solo son fruto de los usuarios, pues requieren de las capacidades tecnológicas de las corporaciones para rastrearlos, extraerlos, almacenarlos y organizarlos.
Sin embargo, la participación de los usuarios en los datos tampoco está lejos de traducirse en una fracción insignificante del valor total de la economía digital. Si bien el valor marginal de cualquier cantidad finita de datos disminuye tendencialmente de forma abrupta, el poder de la última generación del "aprendizaje automático" amplía la capacidad para tareas cada vez más complejas a medida que mejora la calidad y la cantidad de los datos (muchas de las cuales son simplemente imposibles sin grandes cantidades de datos y de numerosos ejercicios de entrenamiento). Esto significa que las retribuciones a los datos pueden disminuir pero solo de forma gradual e incluso pueden ser crecientes si se trata de tareas más complejas con una alta valorización. Estas mediciones en las funciones de producción podrían ser facilitadas por la relevancia de los algoritmos de aprendizaje automático que permite la estimación de los efectos marginales de los nuevos datos en las predicciones. No obstante, se reconoce que aún quedarían muchos retos conceptuales e informáticos por superar.
Otra vía (fuera del dilema entre DcC-DcT) es que la IA no logre su promesa productiva. Sin ir tan lejos, lo que importa es advertir que en caso de alcanzarlo sin una transición a un enfoque de DcT, dejaría a los trabajadores atrapados en los problemas destacados en el enfoque de DcC.
III. ¿Cómo llegamos aquí?
En los incisos arriba se expuso que el DcC es económica y socialmente irracional, pero ahora los autores se preguntan cómo fue que se llegó a tal situación. En la actualidad las experiencias virtuales de los usuarios conspiran con el poder de monopsonio de los gigantes tecnológicos ("servidores sirenas" ver Lanier, 2013) para mantener el status quo. Los autores señalan que la economía de Internet comenzó en gran medida con una burbuja financiera (la llamada crisis dot.com) alimentada con capital de riesgo que perseguía un modelo de negocio con poco sentido. El movimiento social de "software libre" colisionó con una tendencia contracultural en Silicon Valley que exigia que la información fuese gratuita y construyó expectativas sobre los usuarios de los servicios digitales que se ofrecían gratuitamente. En la búsqueda de una manera de monetizar esta actividad, empresas como Google y Facebook se vertieron a la publicidad altamente personificada utilizado los datos de los usuarios. Esto acostumbró a los usuarios a entregar sus datos a cambio de servicios gratuitos, expectativas que han persistido a medida que el valor de tales datos ha aumentado para una mayor gama de servicios de IA.
Este trasfondo histórico ha delimitado las expectativas y las normas, junto con la creación de poderosos servidores sirena (Facebook, Google, Microsoft y otros) que se benefician de la disponibilidad gratuita o extremadamente barata de los datos. Esta es solo una versión extrema de la lógica estándar del monopsonio, pues a diferencia del modelo tradicional de monopsonio que deprime los salarios, los servidores sirena prácticamente eliminan todo salario o remuneración a los usuarios, quienes en su mayoría ni siquiera son conscientes del valor que sus datos crean a diario.
IV. Fuentes de poder compensatorio
La explotación ineficiente del trabajo por altas concentraciones de capital fue un tema abordado por Galbraith (1952) al sintetizar diversas formas del “poder compensatorio”. De ello, los autores proponen tres medidas de “poder compensatorio” para la actualidad:
1) La competencia. Mientras hay empresas que dependen en gran medida del DcC (como Facebook y Google), hay otras que siguen modelos de negocios diferentes (ej. Amazon y Apple), con un enfoque de productividad orientado a que los usuarios se perciban así mismos como productores virtuales. Esto pretende distribuir mayor parte de las ganancias a los trabajadores de los datos que al mismo tiempo incentiva la competencia con la creación de mejores sistemas de inteligencia artificial. Las empresas más pequeñas o las empresas emergentes también podrían marcar la diferencia en asociación significativa con alguna de las empresas de tecnología más grandes.
2) Sindicatos de datos. Los trabajadores de datos podrían organizarse en un "sindicato laboral" que negociara colectivamente con servidores sirena. Una unión podría llamar de manera creíble a una huelga poderosa también podría ser útil para certificar la calidad de los datos y guiar a los usuarios a desarrollar su potencial de ingresos.
3) Regulaciones legales. Los nuevos marcos regulatorios están cambiando los derechos de propiedad de los datos en favor a los usuarios que los generan. Adicionalmente se les exige a las plataformas permitir que sus usuarios comprendan, retiren y transfieran sus datos a otras plataformas. Sin embargo, en la mayoría de las legislaciones existen lagunas que dejan libre el aspecto de los datos. Lo que se necesita son leyes laborales que defienda a los trabajadores contra el monopsonio y al mismo tiempo permita una flexibilidad laboral que requieren los sistemas de datos.
V. Un mercado de datos radical
Las tres medidas de poder compensatorio, según los autores, deben ser coordinadas para encaminarse a un enfoque DcT exitoso. Un mercado radical de trabajo de datos ofrece una oportunidad a corto plazo como problema de investigación, donde la IA tiene el potencial de constituir una fracción significativa del ingreso nacional.
Galbraith, John Kenneth [1952], American Capitalism- The Concept of Countervailing Power, Boston, Houghton Mifflin.
El texto analiza la forma en cómo opera un modelo específico para gestionar los datos bajo propiedad privada de las grandes corporaciones tecnológicas (lo que denominan DcC). En ello la denuncia liberal por un nuevo enfoque que mejore la distribución de la riqueza generada por las nuevas tecnologías digitales (incluidos los datos) es políticamente válida. Un balance crítico de los alcances de la propuesta vislumbra una concentración de poder (económica, política y cultural) verdaderamente global que escapa (en parte) del rango de las regulaciones nacionales, lo que hace que un DcT esté lejos de realizarse o prácticamente imposible.
{kind=link}